Implementing Transformer Model Growth via Layer Stacking in Nanochat
May 1, 2026
Blog Addendum
I’m crossposting here on my blog some amateur LLM research I worked on a couple months ago re-implementing a technique from a research paper. It was implemented on top of Andrej Karpathy’s fairly accessible nanochat repository for training small transformer language models (no relation to the messenger). I originally posted the following write up to a GitHub discussion thread located here.
There has been an idea in deep learning for a while called model growth, which involves training a small neural network that one gradually makes larger as training progresses instead of using a fixed full-size network from the start. It’s an intuitive and biologically inspired idea to try and reduce the amount of training compute needed.
LLM inference has been getting continually more efficient, but tremendous amounts of compute are still needed to create new models. These high resource requirements have obvious first-order effects like higher carbon emissions but also second-order effects like promoting increased economic centralization with few entities able to afford the high cost of model training. Consequently I view any outlandish technique that may make this process more efficient worthy of investigation. And model growth is just an attractive idea that looked like fun to play with :-)
The actual write up starts now below the line 👇
Introduction
This post describes my exploration of depthwise layer stacking during pre-training based on the NeurIPS 2024 paper Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training. The gains I squeezed out of this technique were small, but perhaps this write up will provide a starting point for any future researchers (and autoresearchers) out there.
Code can be found on my fork branch: https://github.com/dvshkn/nanochat/tree/stacking
Concept
The idea is that one can take an already somewhat trained transformer and make it deeper by duplicating its layers in an orderly fashion and then continuing to train it. In the above paper the authors achieved a training speed up of 54.5% using this technique versus training without it.
To illustrate this consider a shallower transformer of depth 4 with its layers.
-> L1, L2, L3, L4 ->
If that transformer gets stacked with a growth factor of 2 into a depth 8 transformer, the layer structure of the new transformer will look like the following, after which training can continue.
-> L1, L2, L3, L4, L1, L2, L3, L4 ->
The authors commonly used a growth factor g=4, but for simplicity I use g=2 for all experiments outlined here. I did perform some runs with g=4, but it did not seem to reveal anything extra.
The authors also investigated a number of different layer ordering schemes including interleaving, but simple repeating of duplicate layers seemed to perform best in their tests. I was curious about interleaving prior to reading the paper and appreciate their thoroughness.
Finally, stacking unavoidably adds two primary hyperparameters to pre-training. The first, already alluded to, is the growth factor (g in the paper). The second is how much to train the initial shallow transformer before stacking occurs (d in the paper).
Implementation
Most of the code is in a new checkpoint manager function called stack_checkpoint() that takes in an existing checkpoint and outputs a new larger checkpoint stacked by some g value. Transformer layer tensors get copied outright, and layer-dependent vectors get extended.
One small additional detail is that Nanochat scales the number of attention heads and the embedding dimension with the number of transformer layers. When training a shallower model in preparation for stacking, it gets trained with the same number of heads that the deeper model will use. I have my own small notation for this where d6s12 indicates a depth 6 model with the proper head dimensions to be stacked into a normal d12.
Lastly, all of the runs hereafter were performed on a single RTX Pro 6000 Blackwell Max-Q. It follows that FlashAttention and FP8 were not used.
Basic Miniseries
To witness the implementation working I ran a simple miniseries comparison for d12, d16, and d20 with default settings. As mentioned above, a growth factor of g=2 was used for the “stackseries” which involved both shallow (half-depth) and deep (full-depth) rounds of training for each given depth. The default value of 10.5 was used for --target-param-data-ratio in all instances.
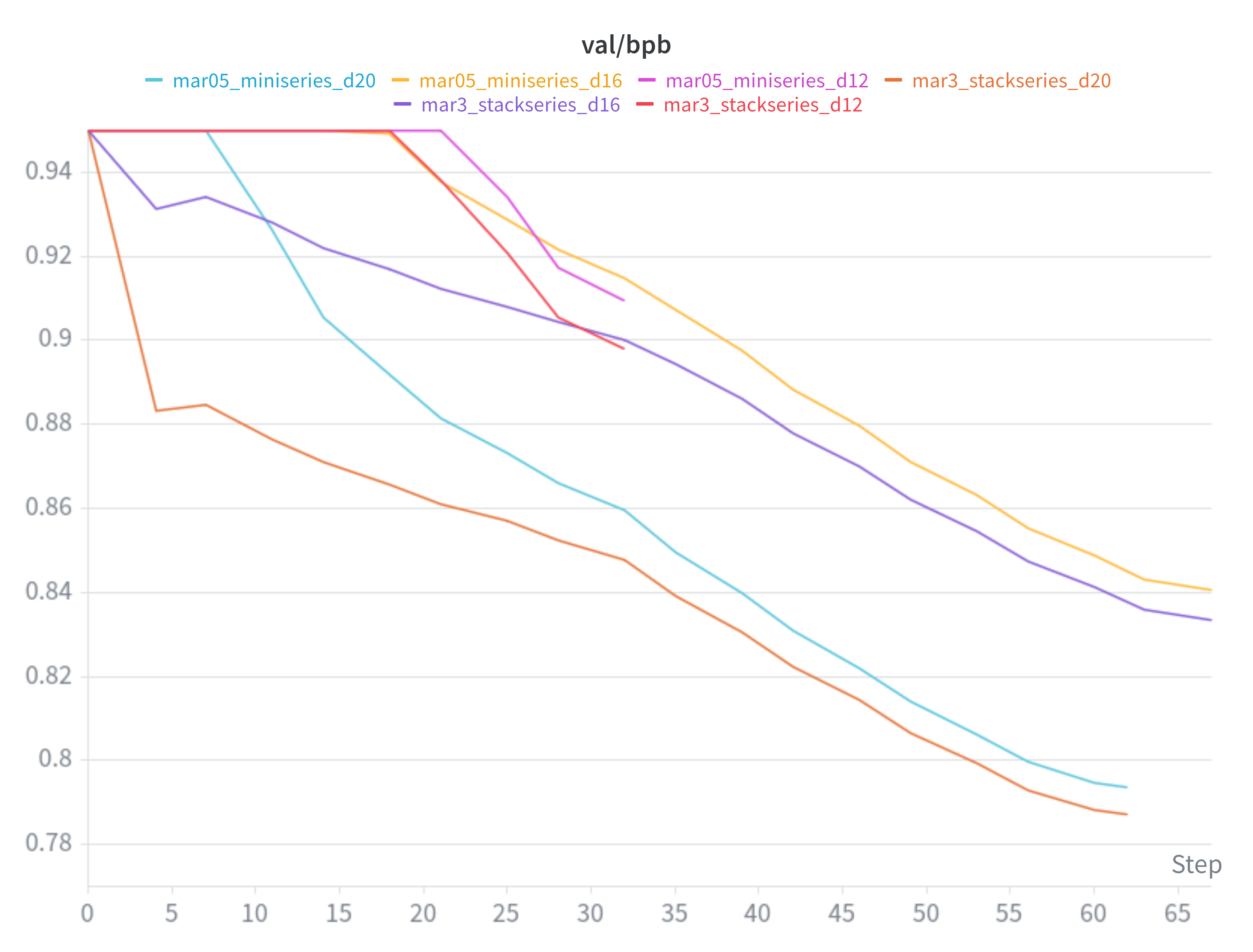
While the stacked models did reach a lower validation loss than their regularly trained counterparts they also consumed more flops due to the additional training of the half-depth model. In that light these results were expected and not impressive.
The main takeaway from this run ended up being that the deep round of training right after stacking started from a much lower loss than the corresponding regular training run.
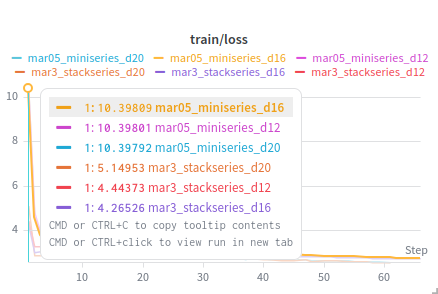
This behavior at least indicated that the stacking implementation seemed to be functioning properly.
Learning Rate
After mulling things over and staring at a lot of log output it seemed like the default learning rate schedule was not ideal. The default value of 0.5 for --warmdown-ratio causes lrm to be held at 1.0 for half of the training duration after which warmdown begins. During the deep round of stacked training it appeared that the loss was floundering during this first half of training when lrm is held high. Because the deep round starts with the model already partially trained it seemed to make sense that the learning rate was not scaling down soon enough.
After some random fiddling that I will skip over I ran a sweep over warmdown ratio values for the stacked training of a d12. For the shallow training round (d6s12) default warmdown ratio was retained. For the deep training round (d12) warmdown ratio was varied from 0.5 to 2.0. Data ratio values were left fixed as indicated in the chart below.
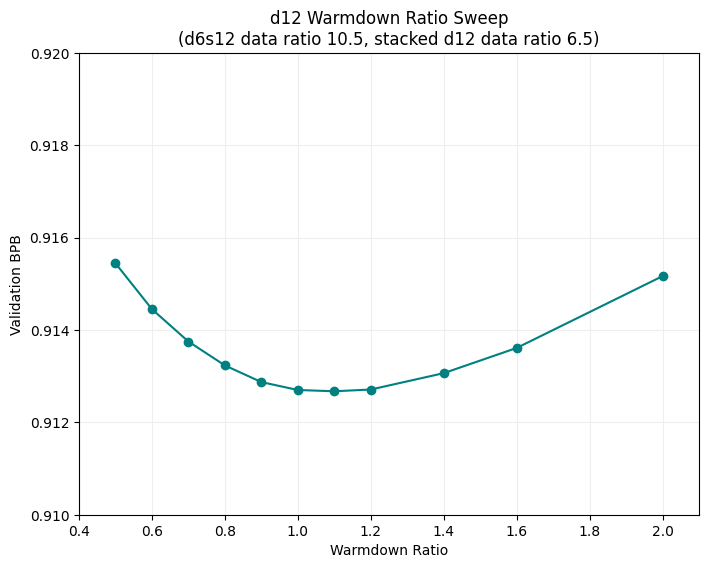
While the val/bpb range was slim, a warmdown ratio of ~1 seemed to perform well. It’s worth pointing out that a value of 1.0 causes the warmdown phase to begin immediately, which does make some intuitive sense. Once stacking occurs midway through training, training resumes on a new checkpoint with a step count reset to zero. In that light these learning rate adjustments are a workaround for an implementation detail.
It’s also worth noting at this point that the val/bpb of a regularly trained d12 (~0.9095) was still beating the stacked configuration. The data ratios used for the above sweep kept total flops at ~98% of a normal training run and allowed for this comparison to start being made.
Early FLOPs
I had a nagging feeling that too many FLOPs were being invested into the shallow round of training. Indeed the authors of the paper trained on vastly fewer tokens before stacking than after (10B tokens for the shallow round and 300B tokens for the deep round).
I decided to try another d12 sweep varying the data ratio used for the shallow round. To keep things fair baseline d12 models were trained with an equivalent number of flops for each point. Default warmdown ratio values were used everywhere except for the deep round of stacked training where a value of 1 was used.
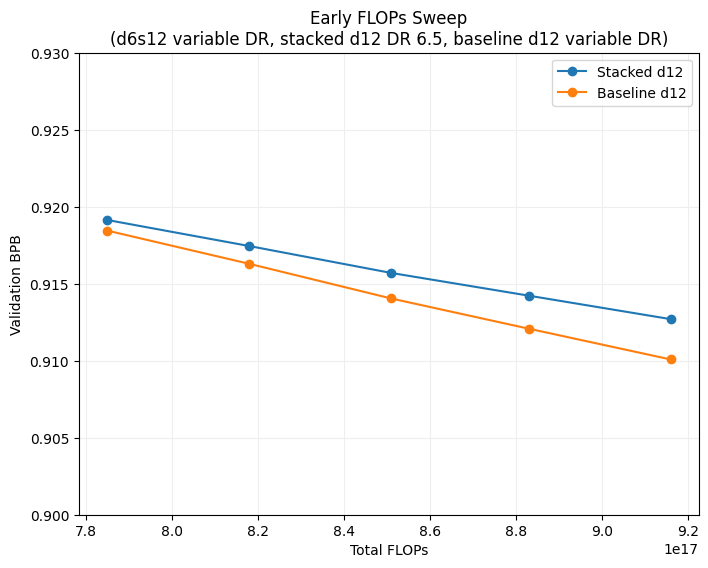
| Total FLOPs | d6 Data Ratio | d12 Data Ratio | Val BPB | Notes |
|---|---|---|---|---|
| 7.85e17 | 6.5 | 6.5 | 0.9191 | |
| 7.85e17 | - | 8.89 | 0.9185 | d12 Baseline |
| 8.18e17 | 7.5 | 6.5 | 0.9174 | |
| 8.18e17 | - | 9.27 | 0.9163 | d12 Baseline |
| 8.51e17 | 8.5 | 6.5 | 0.9157 | |
| 8.51e17 | - | 9.64 | 0.9140 | d12 Baseline |
| 8.83e17 | 9.5 | 6.5 | 0.9142 | |
| 8.83e17 | - | 10.00 | 0.9121 | d12 Baseline |
| 9.16e17 | 10.5 | 6.5 | 0.9127 | |
| 9.16e17 | - | 10.38 | 0.9101 | d12 Baseline |
Results were very close, but there was a slight trend showing that increasing data ratio in the shallow round resulted in worse val/bpb compared to baseline. This implies that for stacked training it’s desirable for the shallower model to be undertrained. The question of how undertrained the model should be was not quite answered.
As an aside, I was pretty ready to be done with the project at this point. I walked away for about a week before actually charting the data as shown above. Seeing the lines almost cross on the left side convinced me to design one last sweep. Admittedly, I did also want to beat the baseline val/bpb even if only by a minuscule amount.
Fixed FLOPS
This last sweep needed to bring the shallow round FLOPs down really low. Data ratios ranged from 1.25 to 5.25 for the shallow round and a complementary data ratio was used for the deep round to bring the total flops to 9.27e17 (equivalent to data ratio 10.5 for d12).
On a hunch I tested an additional change to the learning rate schedule by using a warmdown ratio of 0 for the shallow round which functionally disabled warmdown all together. A warmdown ratio of 1 was retained for the deep round. Across both rounds this configuration fuzzily mimicked Nanochat’s default learning rate schedule.
For confidence I ran this sweep both with and without this extra warmdown change. It turned out that disabling warmdown for the shallow round performed better, and this is the configuration shown below.
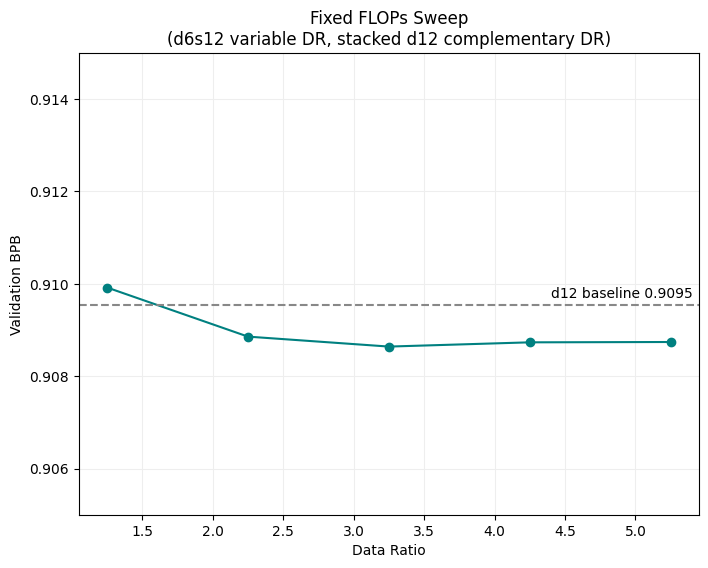
| d6 Data Ratio | d12 Data Ratio | Val BPB | Notes |
|---|---|---|---|
| 1.25 | 10.04 | 0.9099 | |
| 2.25 | 9.67 | 0.9089 | |
| 3.25 | 9.30 | 0.9086 | |
| 4.25 | 8.93 | 0.9087 | |
| 5.25 | 8.56 | 0.9087 | |
| - | 10.5 | 0.9095 | d12 Baseline |
This stacked training configuration just barely beat the baseline d12 model. A data ratio of 3.25 for the d6s12 model performed best, and as one would expect going too low on the data ratio became detrimental. Success!
The last item remaining was to compare results with the original paper. The authors measured training acceleration (or deceleration) as when the stacked training loss reached a value equivalent to the final training loss achieved by a non-stacked configuration. With some simple searching through the training logs I calculated a similar figure for my Nanochat stacking implementation.
Baseline d12 Loss: 2.980
Stacked d12 Equivalent Step: 1835/1953
Stacked d12 FLOPs: 8.21e17
d6s12 FLOPs: 1.06e17
Relative Stacked Compute Used:
((1835/1953) * 8.21 + 1.06 ) / 9.27 = 94.6%
Compute Acceleration: 5.4%
Final Remarks
My best pre-training run with stacking showed a 5.4% compute acceleration over Nanochat’s baseline d12 pre-training. This was nowhere close to the 54.5% acceleration observed in the NeurIPS paper. It’s safe to say that I was not able to get the paper’s results to reproduce within Nanochat.
There were some hyperparameter differences between my setup and the authors’. The model trained in the paper had more parameters and was trained on more tokens, and the stacking in the paper also used a larger growth factor. So it is possible that there still exists some regime under which stacking shows more promise.
If people have any questions, comments, or ideas feel free to post them below!
As you may have realized there isn’t a place here to directly post comments, but feel free to reply to the original GitHub discussion or reach out on Mastodon or Bluesky.